随机写点东西
我觉得是时候给刚学会 的ai绘画技巧做个归档了(不然以后忘了就又要重来了)
开始部署
我的系统信息
系统:Windows10
GPU:RTX3060ti
准备工作
安装anaconda
访问anaconda官网直接下载安装,建议使用IDM或者挂梯
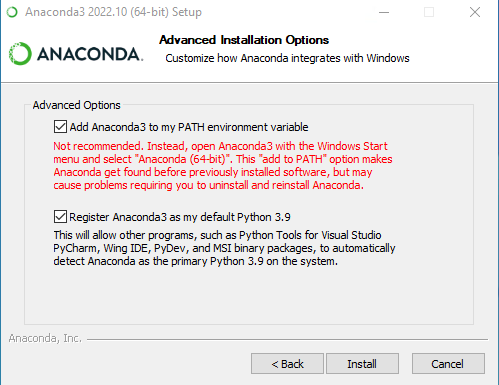
安装时建议选择just me,这样更方便添加环境变量
勾选添加到path
网络
1.最好准备一把梯子
2.对conda和pip进行换源
conda换源
打开Windows终端,输入以下命令输出.condarc文件
1 | conda config --set show_channel_urls yes |
打开C:\users\你的用户名\.condarc
粘贴以下内容(换为清华源)
1 | channels: |
pip换源
在C:\users\你的用户名\AppData\Roaming中新建或打开pip文件夹,在里面新建或修改pip.ini文件,粘贴以下内容
1 | [global] |
正式开搞
1.环境配置
打开anaconda,新建一个环境,python版本选择3.10.8。不能用base环境因为base环境python版本为3.9,使用Stable Diffusion webui需要3.10.6以上
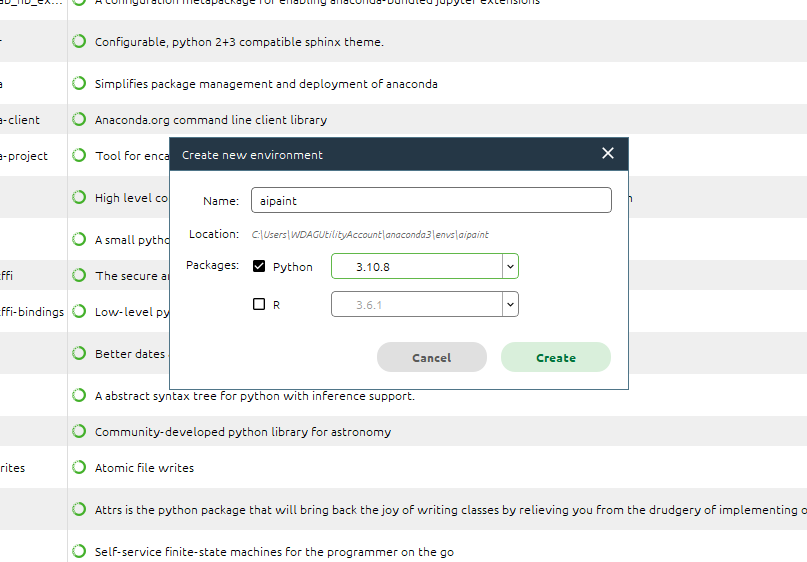
当然你也可以在命令行创建环境
配置环境时先clone项目仓库
1 | git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git |
进入项目仓库,右键「在终端中打开」,如果你没有这个选项,就按住shift右键在powershell中打开
激活创建好的环境
1 | conda activate aipaint |
执行以下命令安装依赖项(如果的依赖项要求有改动,请改为最新要求)
1 | conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.6 -c pytorch -c conda-forge |
如果换源成功的话安装过程是很快的
2.模型下载
推荐下载novelai泄露的模型
1.novelai模型:包括 4g的一般模型animefull-final-pruned和7g的animefull-final-latest模型
2.stable diffusion模型:前往huggingFace
这两个模型一个是毕竟小的,一个是比较大 的,自己选着下(需要注册huggleface账号)

3.Waifu Diffusion模型:下载地址,选择性下载.ckpt后缀的文件
3.运行
然后,在命令行输入webui.bat运行安装脚本(不要直接双击,否则会使用默认环境中的python3.9)然后脚本就会自动安装剩余的依赖项并运行Stable Diffusion webui
当你看到命令行输出以下内容时就部署完毕且成功运行了
1 | Installing requirements for Web UI |
你需要知道的一点:webui的脚本在初次运行时其实在项目目录新建了一个虚拟环境(venv)因此此后每一次运行webui只需要双击打开webui.bat文件即可
4.额外配置
安装deepbooru和xformers
编辑项目目录下的webui-user.bat文件
它里面原本应该是这样的(没有中文)
1 | @echo off |
python路径: 填<webui的目录路径>\venv\Scripts\Python.exe,例如H:\stable-diffusion-webui\venv\Scripts\Python.exe
git路径: 一般不用管
虚拟环境所在目录名称: 默认为venv,不用修改
你要附加的命令: 我们要安装deepbooru和xformers所以在这里填上--deepbooru --xformers
改完之后就是这样的:
1 | @echo off |
保存退出然后运行它就可以完成安装了(如果安装失败可能是网络问题)
是时候玩了
打开127.0.0.1:7860进入webui页面
简单介绍
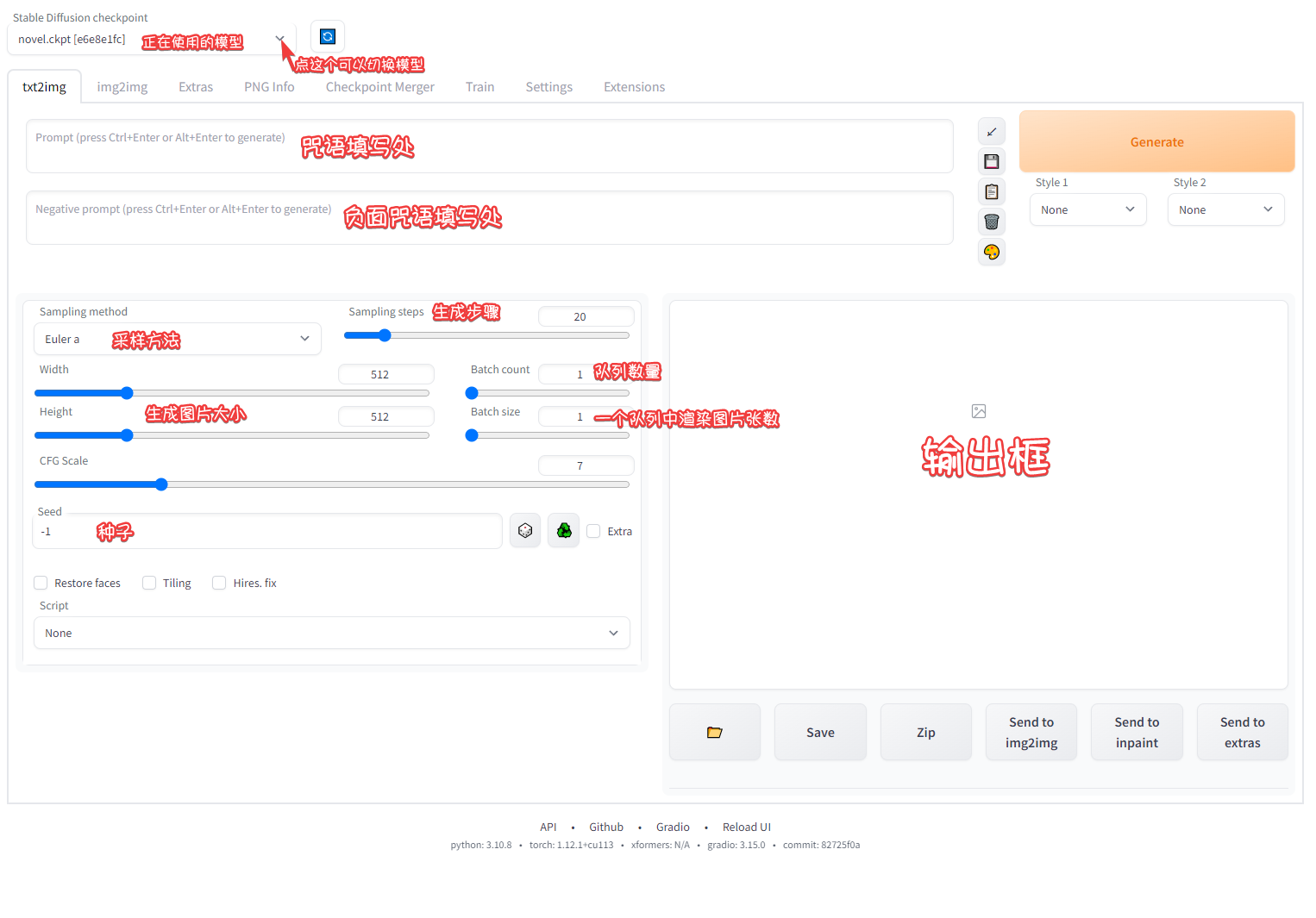
特别说明:
Sampling method: 采样方法。不同的采样方法得到图片的效果不同,二次元一般用Euler_a和DDIM
Sampling steps: 生成步骤。越高代表细节越丰富,但过高不一定就很好,一般在30左右
CFG Scale: 数值越高图像越接近关键词描述的内容,同时会影响柔和度和清晰度,Scale值越高我感觉图会看起来更清晰,也就是线条会更加明显。
Batch count: 队列数(一般为1就好了)
Batch size: 单个队列中生成多少张图
Seed: 填写种子。可以填入别人的种子,使用种子可以获得相似的出图效果
输入咒语就可以开始生成图片啦!
特别推荐
大佬开发的写咒语网站AI词汇加速器,可以快速生成咒语
常用咒语:
1.一般默认正面咒语:
1 | {an extremely delicate and beautiful girl}, 8k wallpaper, {{{masterpiece}}} |
2.标准负面咒语:
1 | lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry |
embedding的使用
embedding,也就是一般私炉炼出来的丹,负载在模型上使用
在网络上下载后缀为.pt的文件后。将其放入webui目录下的embeddings文件夹中即可使用
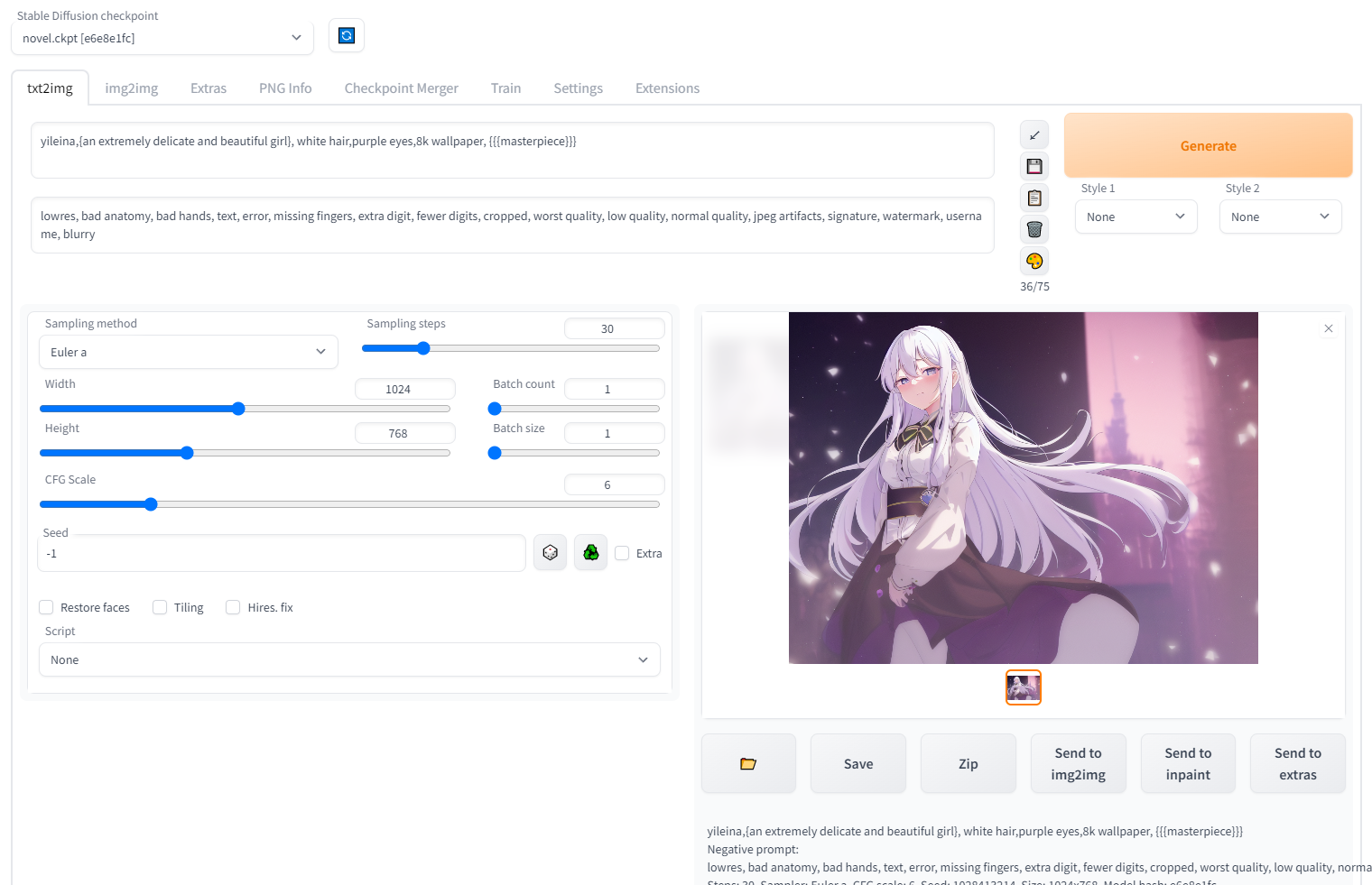
使用embedding时只需在正面咒语的框内输入制作者炼制时使用的prompt即可
例如我现在下载了一个伊雷娜的embedding,我只需使用``yileina```,就可以使用它了

embedding的炼制
如果网上找不到你需要的embedding,那是时候来当炼金师了
准备工作
首先你要找图
1.可以取pixiv抓取画作(推荐使用Powerful Pixiv Downloader)
2.或者取e站下图包(里站)
然后对图片进行筛选和预处理
1.请筛选出人物突出(单人),背景比较干净的图片,不要出现边框、文字等内容
2.对于背景比较复制的图片可以使用rembg去除背景
安装过程非常简单,按照README就行了(注意先装onnxruntime-gpu,README里有说)
然后在终端进入你放选好的图片的文件夹(pic)的前一个文件夹,新建一个放置处理后文件的文件夹
1 | rembg p pic picok1 |
记得看一下处理情况,有些如果处理得比较差的话可以考虑用回原图
3.裁剪:建议用这个网站手动裁剪,当然你也可以到下一步让webui来剪
用网站裁剪记得将图片大小调为512x512,处理完将图片存储到一个新的文件夹(我命名为picok2)
调整webui设置
打开setting选项卡,点Training,勾选Move VAE and CLIP to RAM when training if possible. Saves VRAM. (这个操作可以在训练时节省显存),然后点Apply settings确认修改。
正式开始
点Train选项卡
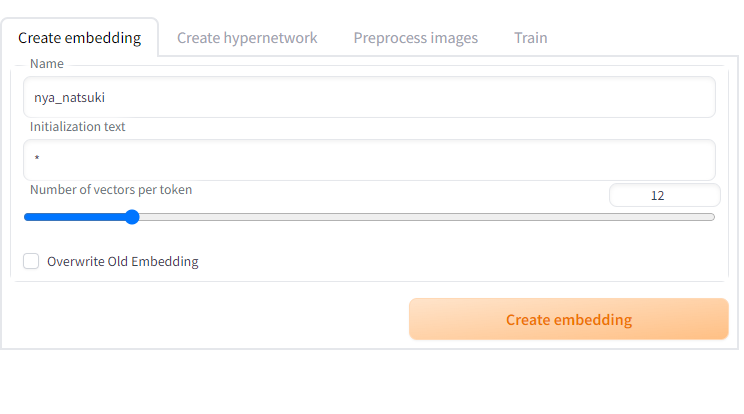
输入你要训练的embedding的名称,它将会作为你后续使用这个embedding时的prompt
在Number of vectors per token中,如果你是训练人物,建议在6以上,如果是画风建议在10以上
点击Preprocess images预处理图片
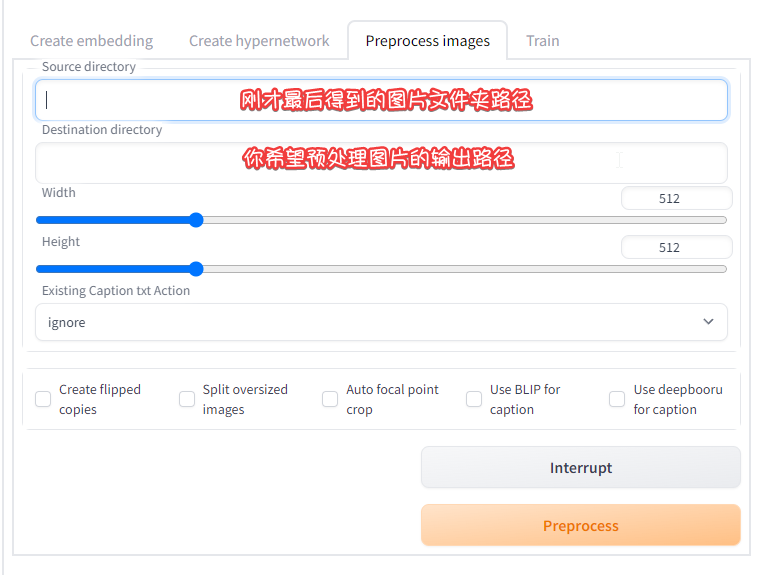
Create flipped copies: 创建镜像图片。建议勾选,能得到双份样本。
Split oversized images: 把过大的图片裁切成多张。我们已经切好图片了,所以不需要。
Auto focal point crop: 自动聚焦,就是自动截出过大的图片的重点部分(ai认为的重点)。我们同样不需要
Use BLIP for caption: 和 Use deepbooru for caption 建议勾选,特别是deepbooru对于二次元炼丹有帮助
点preprocess进行预处理
点train进入训练选项
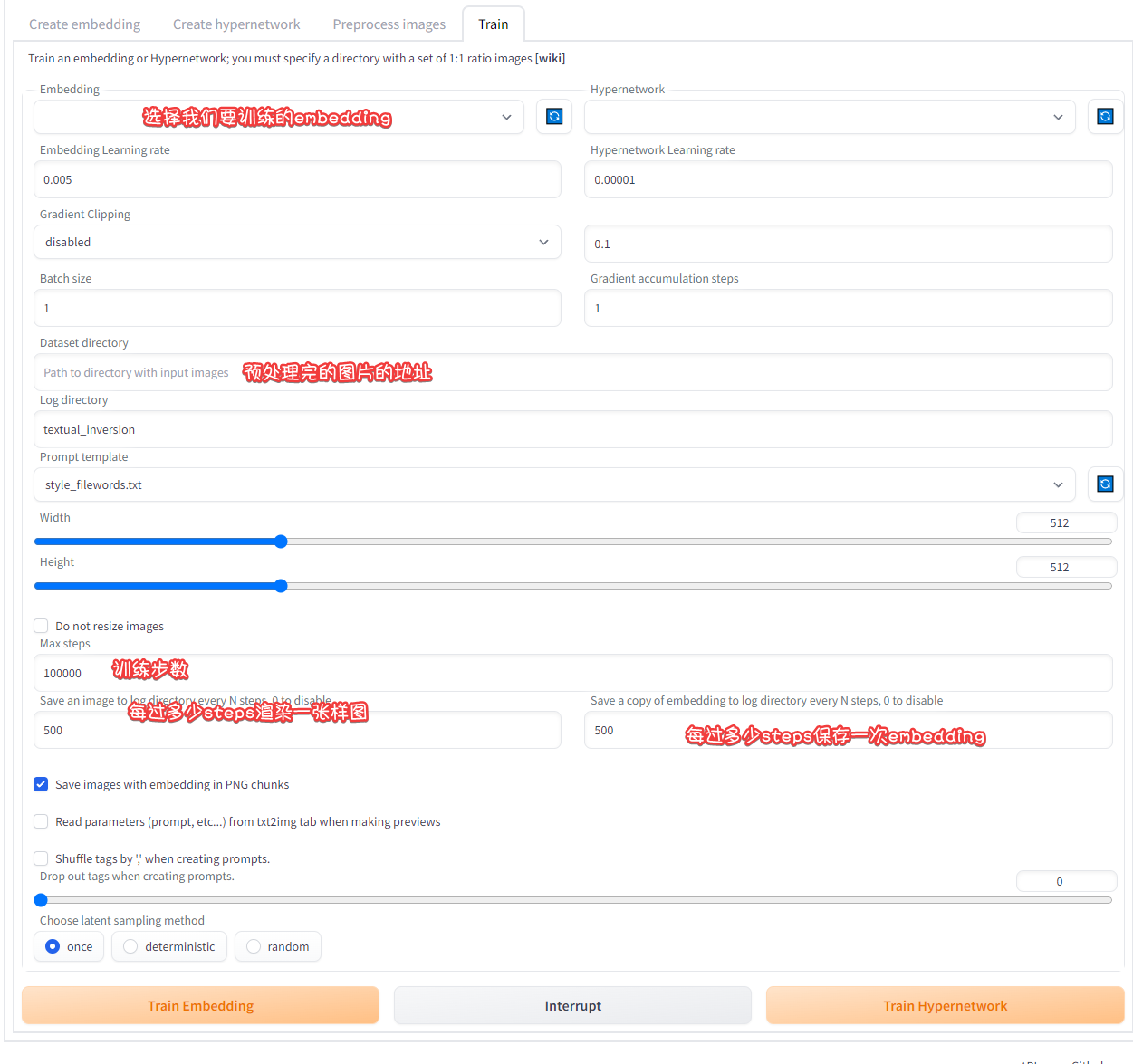
未完待续…
